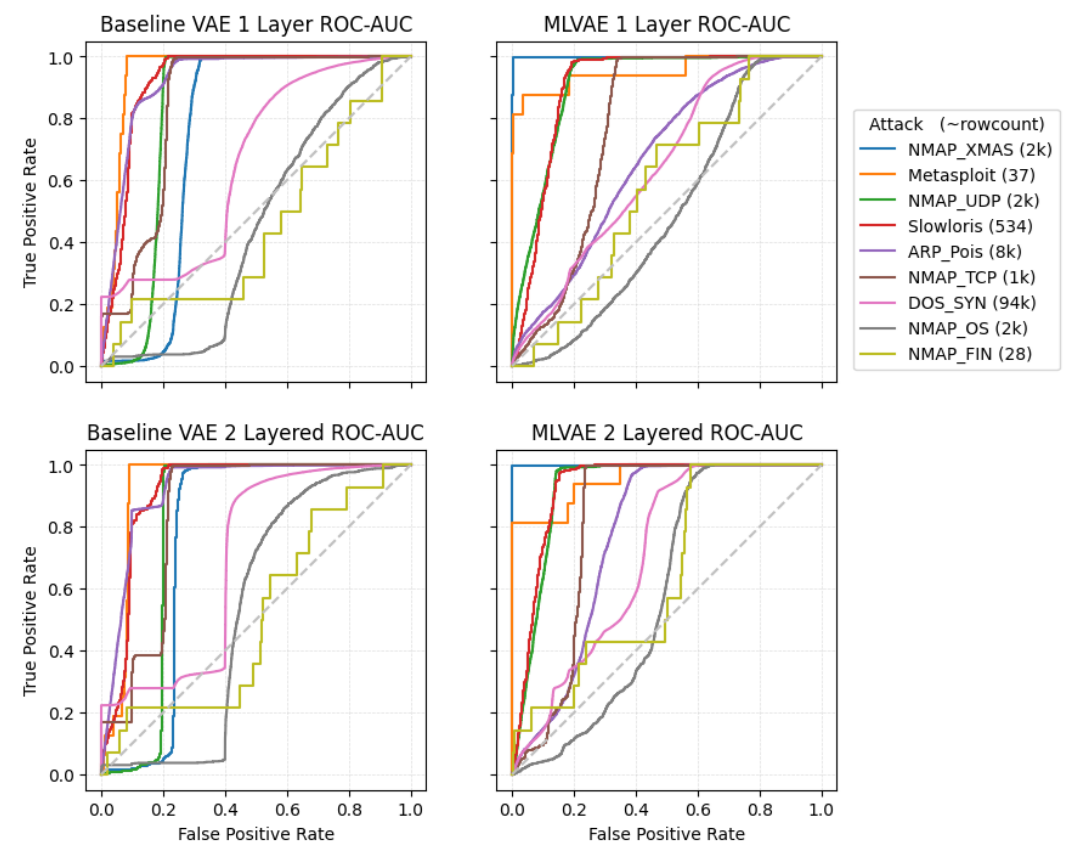
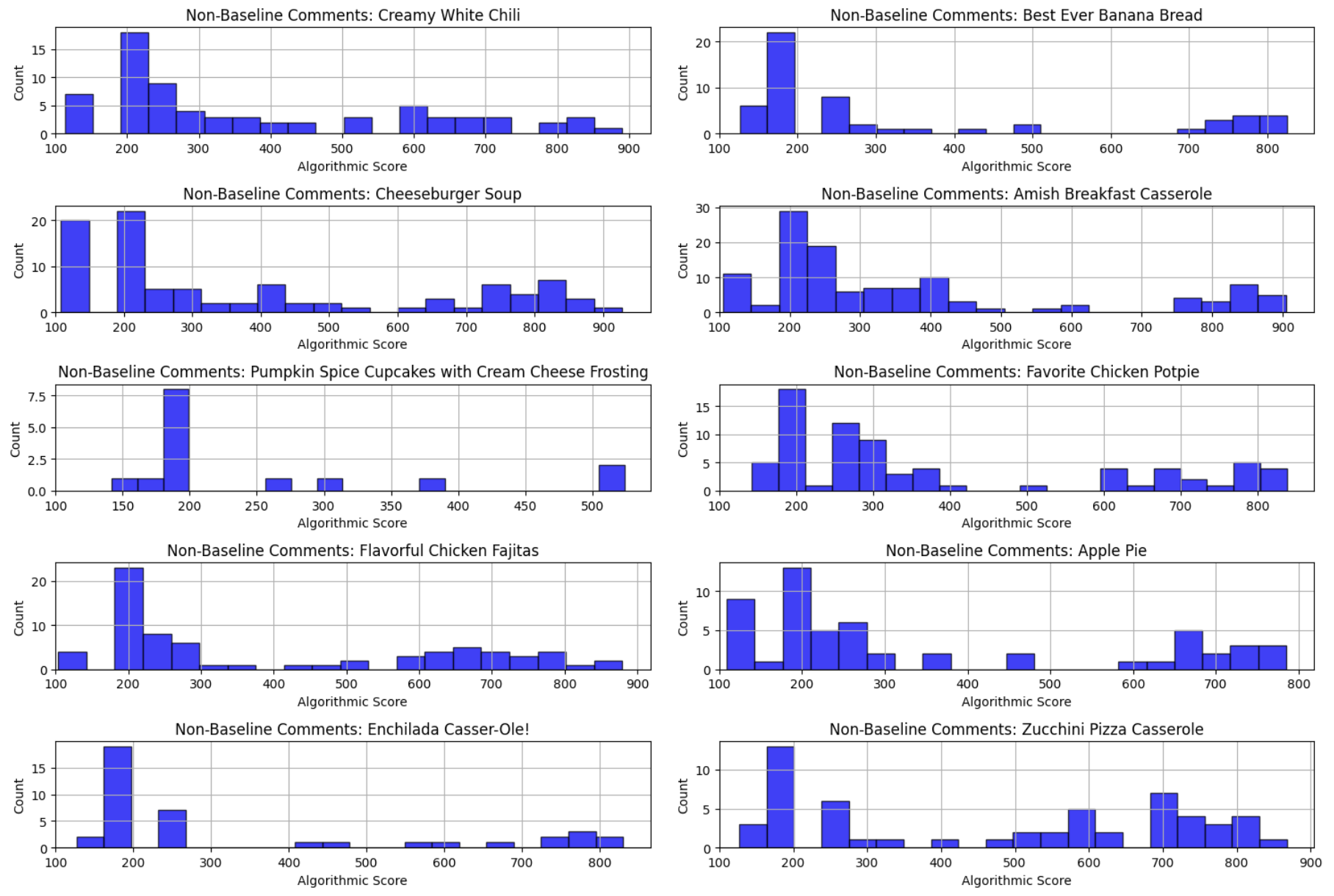
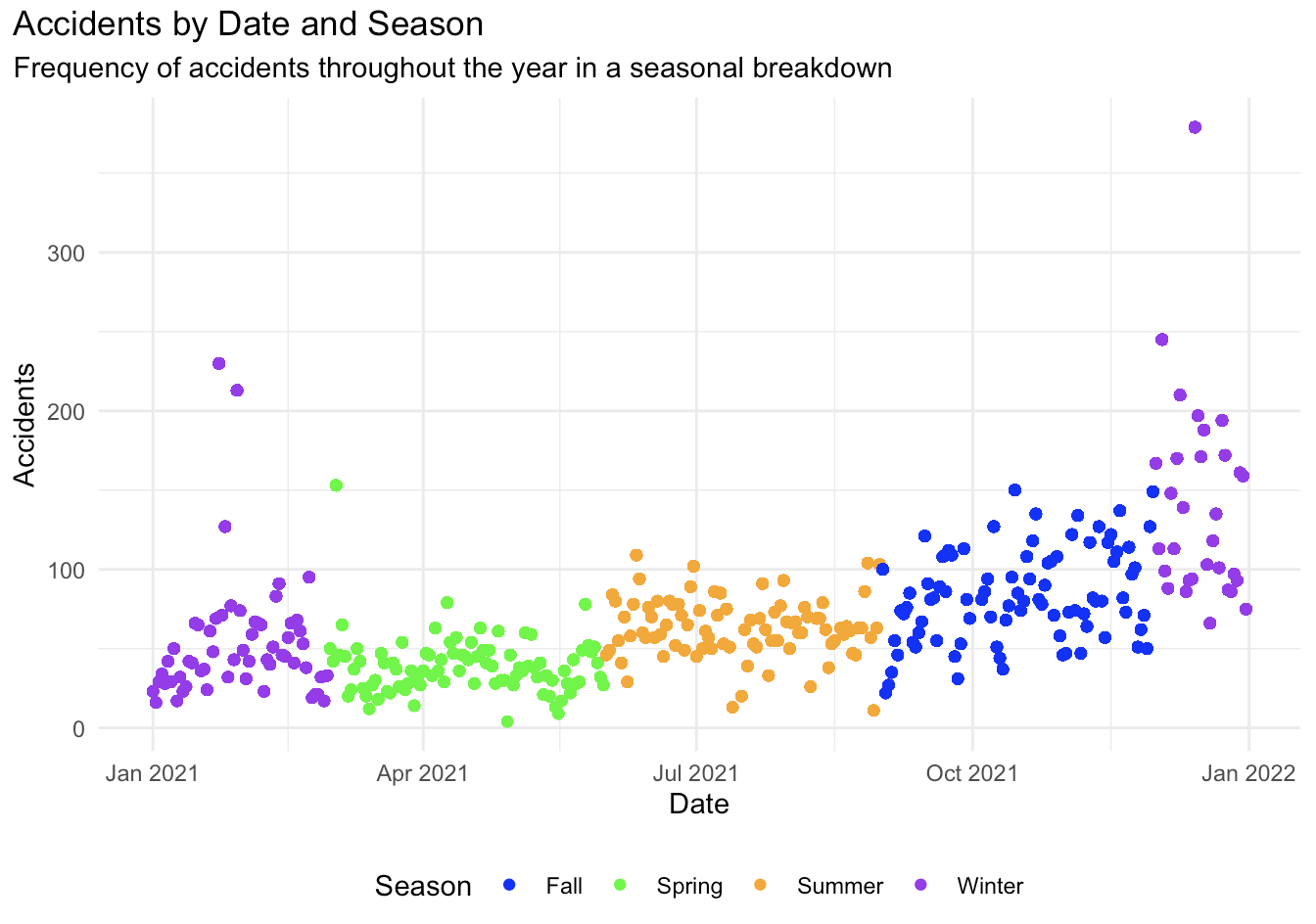
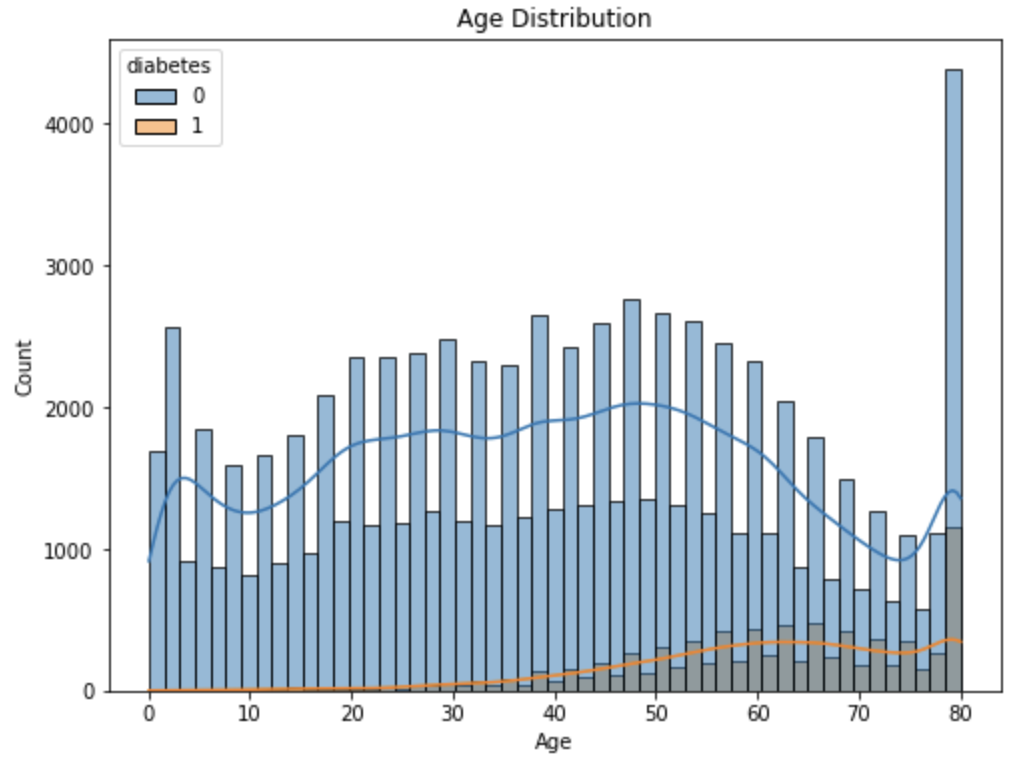
Get to know me:
I have always been fascinated by the power of data—its ability to tell stories, uncover patterns, and drive meaningful decisions. Whether solving complex problems, extracting hidden insights, or making sense of vast amounts of information, I am passionate about transforming raw data into actionable knowledge. With a strong foundation in data science, I specialize in data manipulation, data visualization, statistical analysis, and machine learning. My hands-on experience spans across various tools, including Python, R, SQL, Spark, BigQuery, and Google Cloud Platform (GCP), along with key libraries such as Pandas, Matplotlib, Scikit-learn, and Pytorch. These tools are my go-to for working with both structured and unstructured data, building predictive models, and developing data-driven strategies that inform decision making.
Beyond data science, there's much more to know about me. I have over 16 years of experience in water polo, including four years as a Division 1 student-athlete at UC San Diego. This experience shaped my soft skills in communication, teamwork, time management, leadership, and discipline, all while fostering a strong work ethic and resilience. These qualities enable me to excel under pressure and in fast paced environments. When I'm not immersed in data, I enjoy staying active and practicing my hunter-gatherer skills through freediving, spearfishing, lobstering, and fishing. There's something uniquely fulfilling about sustainably providing my own meals.